Streaming data from MSSQL to Grafana’s InfluxDB using Apache Nifi


MSSQL continuously receives new time-series data. We are going to use Apache NIFI to regularly retrieve the new data from MSSQL and dump the data into INFLUXDB, so that GRAFANA can generate the chart for the dashboard.
APACHE NIFI PROCESS FLOW

- QueryDatabaseTable Configuration
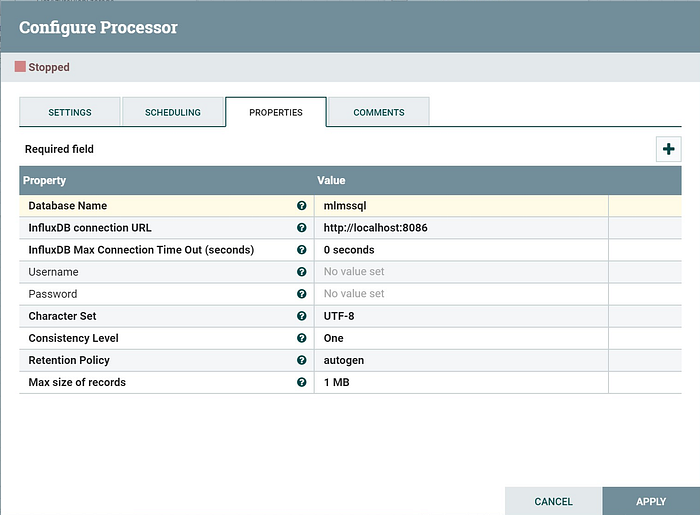
This is the first processor we are going to configure. It is perhaps the most confusing one. Misconfiguration means no data will be pulled and no data for Grafana.

The first property Database Connection Pooling Service needs further configuration [after you create a new value for it]. You click on the little Right Arrow on the right, to get to the connection pool configuration page.

Click on “Gear” to configure.
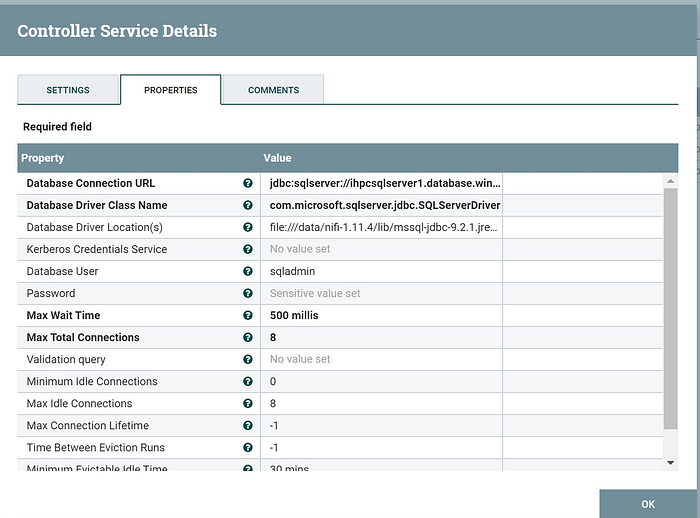
I retype the value of the value for clarity.
Database Connection URL: jdbc:sqlserver://ihpcsqlserver1.database.windows.net;databaseName=mltable
Database Driver Class Name: com.microsoft.sqlserver.jdbc.SQLServerDriver
Database Driver Locations: file:///data/nifi-1.11.4/lib/mssql-jdbc-9.2.1.jre8.jar
You can download the driver jar file from https://docs.microsoft.com/en-us/sql/connect/jdbc/download-microsoft-jdbc-driver-for-sql-server?view=sql-server-ver15
In my case, I am using OpenJDK version “1.8.0_292” and it is compatible with mssql-jdbc-9.2.1.jre8.jar
Database User and Password: your database user and password
After you configured the parameters above, you need enable it by clicking on the “Electrical Icon” on the right, just beside the “Gear Icon”
2. SplitAvro Configuration
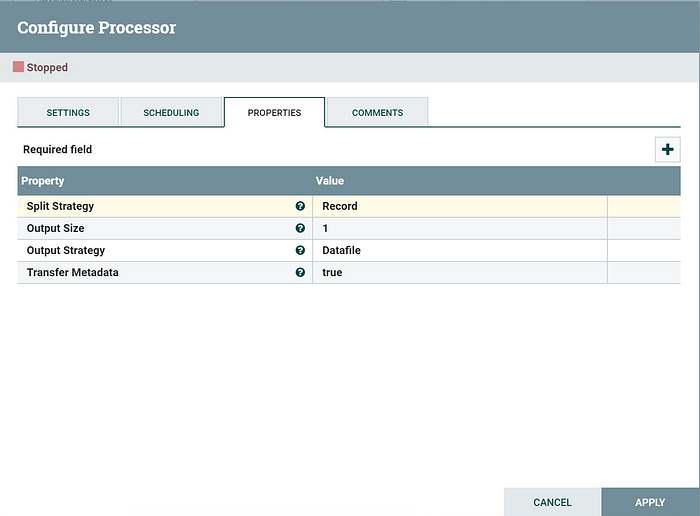
3. ConvertAvroToJSON Configuration
4. ExecuteStreamCommand Configuration
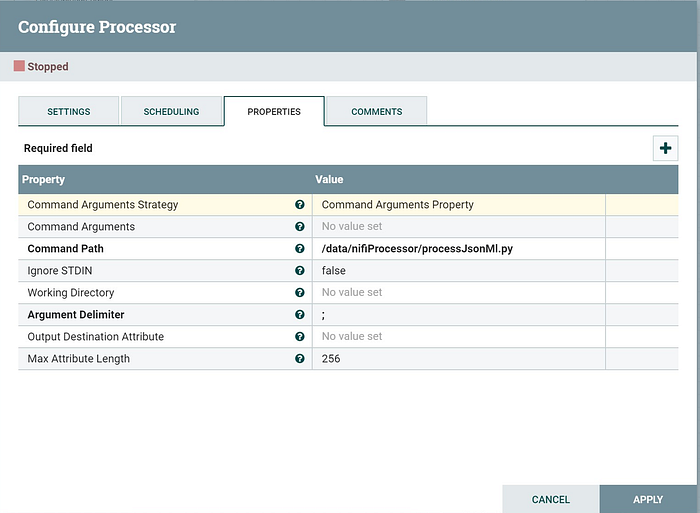
We execute processJsonMl.py to process the JSON output to InfluxDB text format, which be process by the next step.
processJsonMl.py
#!/home/juniarto/anaconda3/bin/pythonimport sys
import json
import pandas as pd
from datetime import datetimemyMsg = json.loads(sys.stdin.readlines()[0])MSG_TXT = '{device_id} temperature={temperature},pressure={pressure},predicted={predicted} {timestamp}'
TimeString = myMsg['TimeValue']
datetime_object = datetime.strptime(TimeString, '%Y-%m-%d %H:%M:%S.%f')
msg_text_formatted = MSG_TXT.format(device_id='opcuadev1', temperature=float(myMsg['Temperature']), pressure=float(myMsg['Pressure']), predicted=float(myMsg['Predicted_Pressure_Using_Temperature']), timestamp=int(datetime_object.timestamp()*1000000000))
print(msg_text_formatted)
5. PutInfluxDB Configuration